Ingest Data
You can upload data to an input repo in Pachyderm by using Console or the PachCTL CLI. Console offers an easy-to-use interface for quick drop-in uploads, while the PachCTL CLI provides more advanced options for uploading data by opening commits and transactions.
Before You Start #
- You must have a running Pachyderm cluster.
- You must have created a project and repository.
- Pachyderm uses
*?[]{}!()@+^as reserved characters for glob patterns. Because of this, you cannot use these characters in your filepath.
How to Ingest Data #
Via Console #
- Open Console.
- Scroll to a project you wish to upload data to and select View Project.
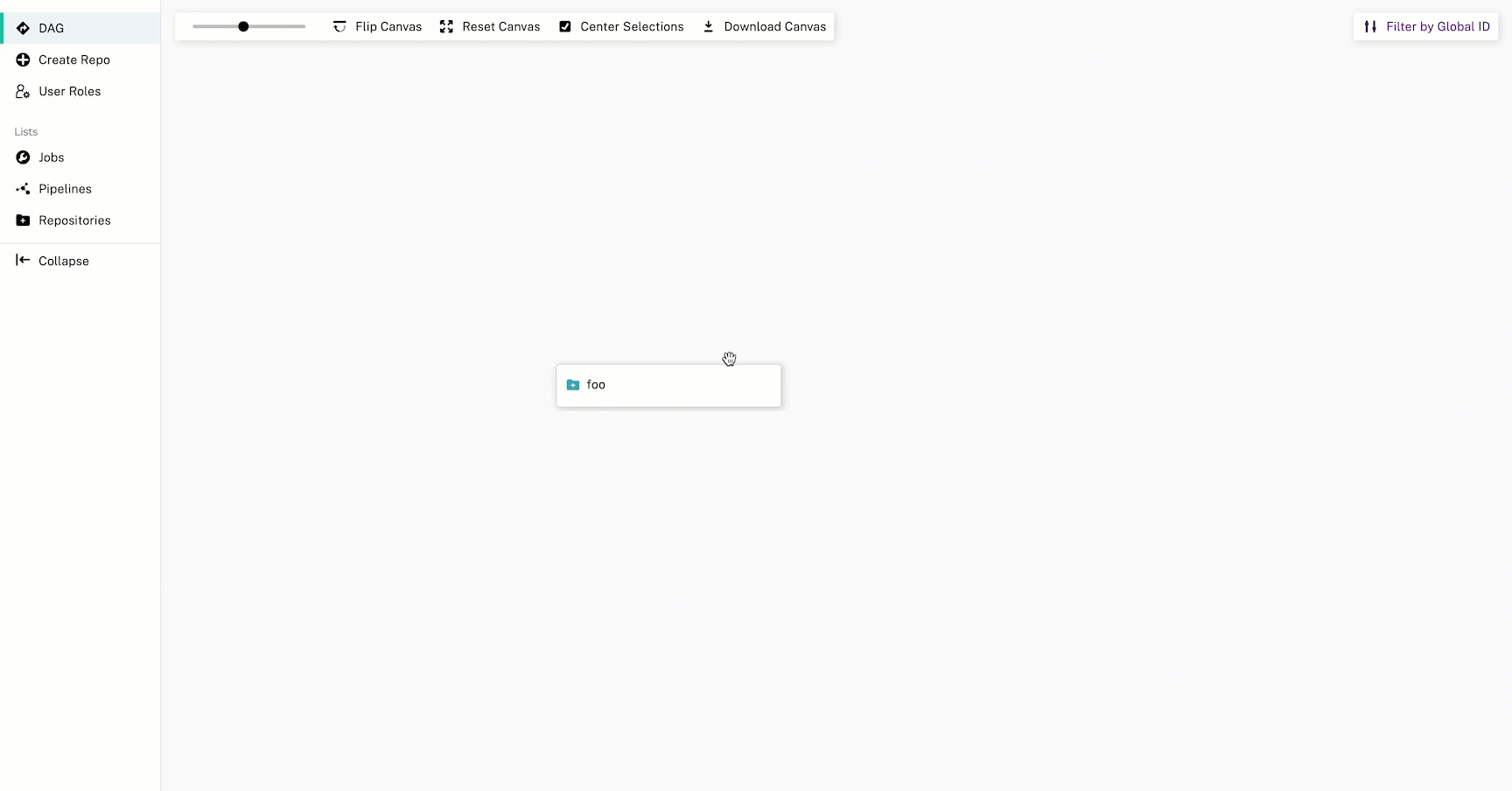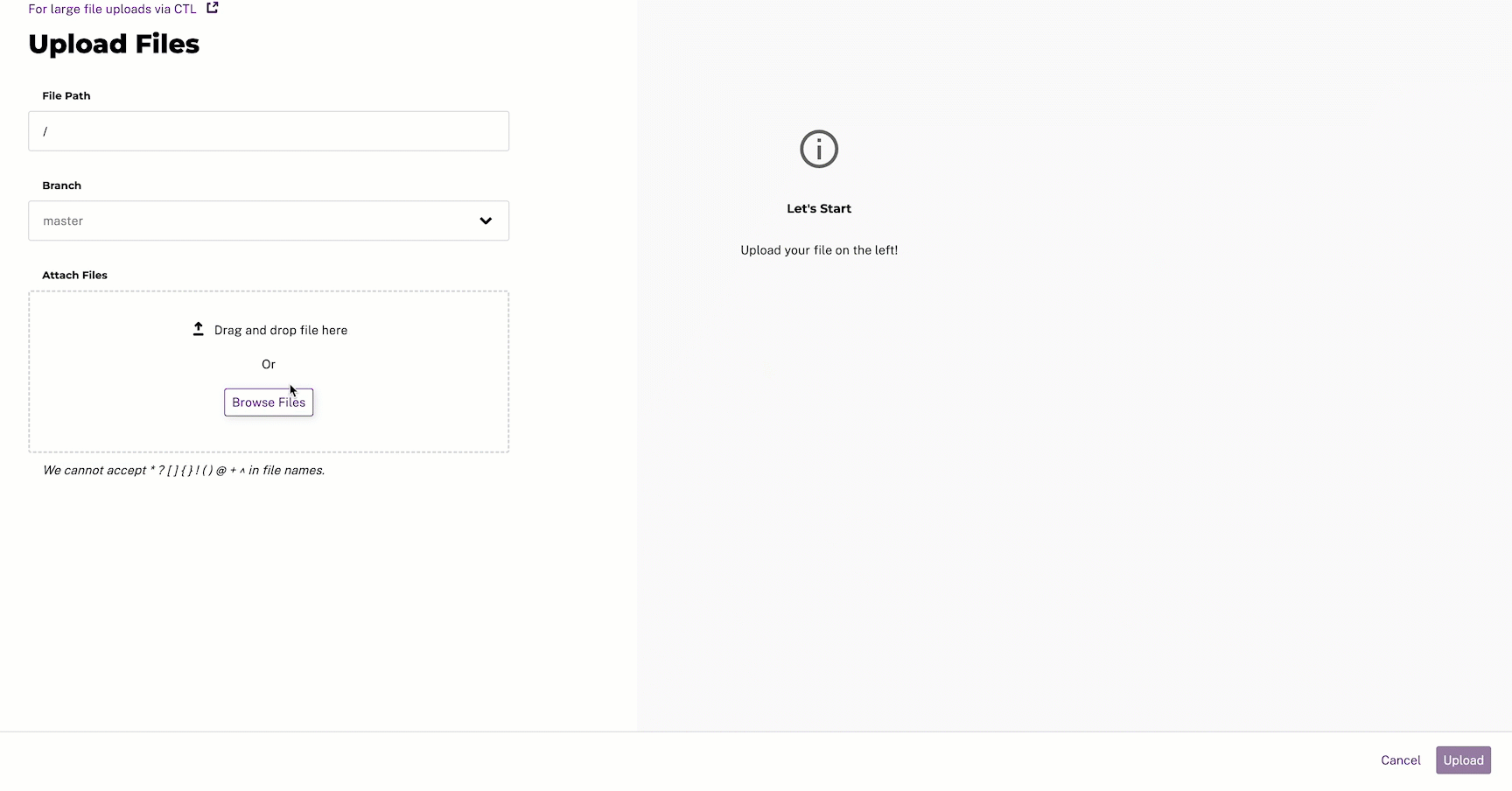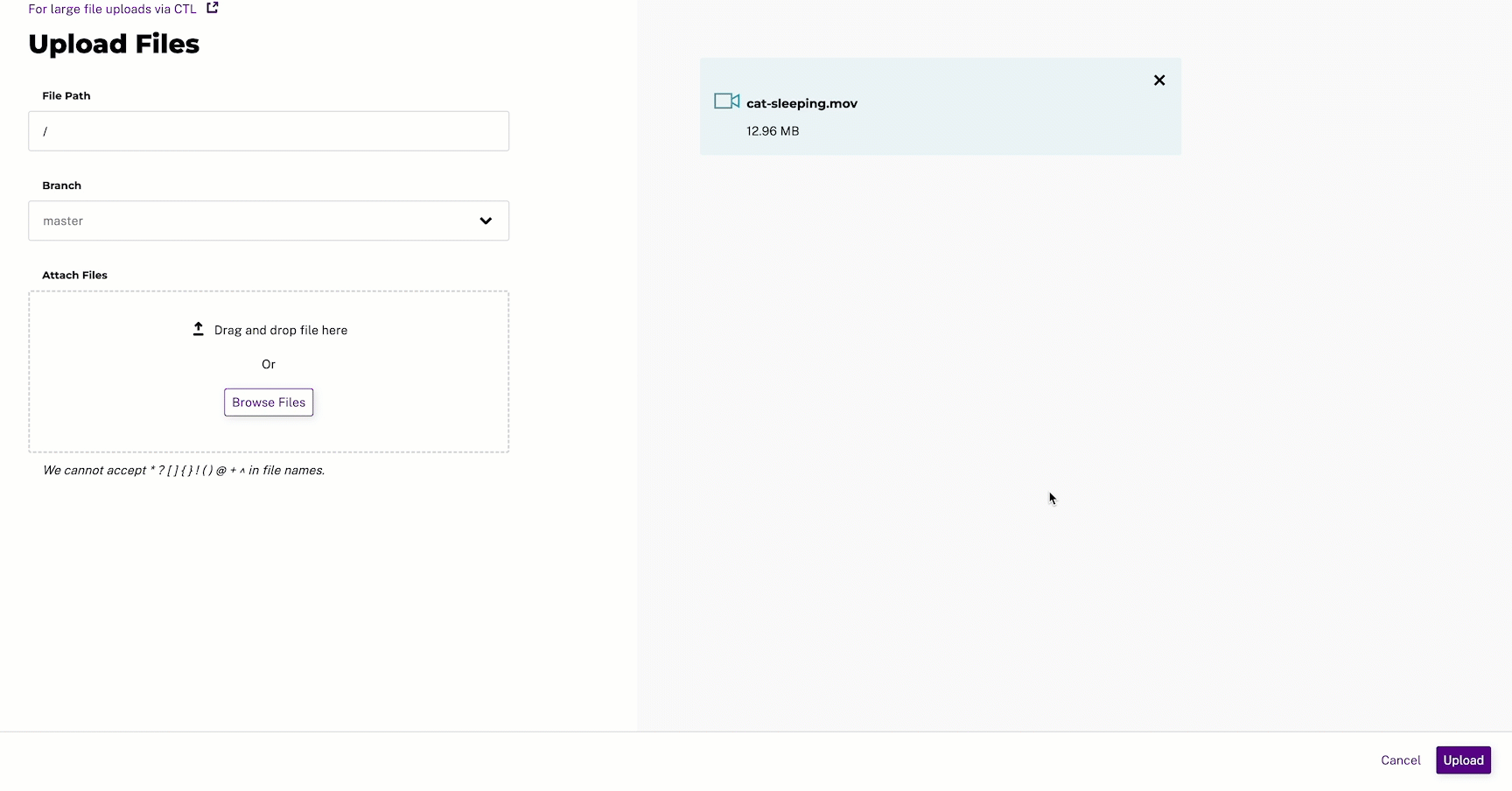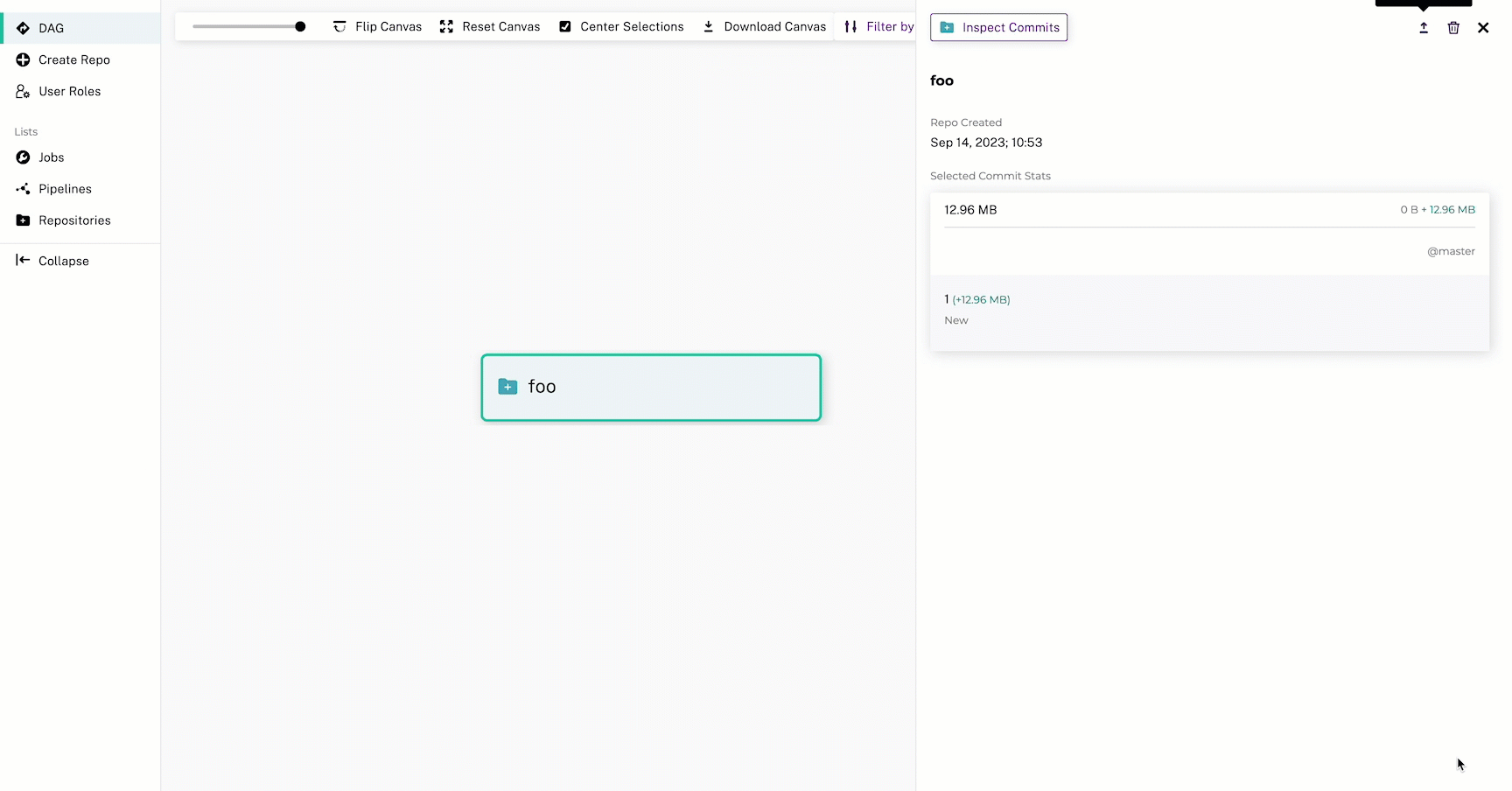
- Select a repository from the DAG view.
- Select Upload.
- Optionally, provide a File Path to upload your data to a specific directory in the repository.
- Select an existing Branch; defaults to
master. - Select Browse Files and select the files you want to upload.
Via PachCTL #
For a comprehensive list of options for pachctl put file, see the CLI Reference.
Atomic Commits #
Atomic commits automatically open a commit, add data, and close the commit. They are typically useful when you only need to submit one file or directory – otherwise, you should use manual commits to avoid noisy commit history and overwhelming your pipeline with many jobs.
- Open terminal.
- Run the following command:
pachctl put file <repo>@<branch>:</path/to/file1> -f <file1>
Manual Commits #
Manual commits allow you to open a commit, add data, and close the commit when you are ready. They are typically useful when you need to submit multiple files or directories that are related. They also help your pipeline process your data faster by using only one job to process all of the data.
- Open terminal.
- Run the following command:
pachctl start commit <repo>@<branch> - Add multiple pieces of data:
pachctl put file <repo>@<branch>:</path/to/file1> -f <file1> pachctl put file <repo>@<branch>:</path/to/file2> -f http://file_2_url_path pachctl put file <repo>@<branch>:</path/to/file3> -r -f s3://file_3_obj_store_url/upload-dir pachctl put file <repo>@<branch>:</path/to/file3> -i -f gcs://file_4_obj_store_url/dir-contents-ony pachctl put file <repo>@<branch>:</path/to/file3> -f as://file_5_obj_store_url - Close the commit:
pachctl finish commit <repo>@<branch>
If you have a large dataset and you wish to only upload a subset of it, you can add a metadata file containing a list of urls/paths to the relevant data. Your pipeline code will retrieve the data following their path without the need to preload it all.
In this case, Pachyderm will not keep versions of the source file, but it will keep track and provenance of the resulting output commits.
Transactions #
Transactions allow you to bundle multiple manual commits together and process them simultaneously in one job run. This is particularly useful for pipelines that require multiple inputs to be processed together instead of kicking off a job each time only one of the inputs has been updated.
- Open terminal.
- Run the following command:
pachctl start transaction - Open commits and add data:
pachctl create branch <repo>@<branch> pachctl start commit <repo>@<branch> pachctl put file <repo>@<branch>:</path/to/file1> -f <file1> pachctl finish commit <repo>@<branch> pachctl start commit <repo>@<branch> pachctl put file <repo>@<branch>:</path/to/file2> -f <file2> pachctl finish commit <repo>@<branch> - Close the transaction:
pachctl finish transaction