
You can interact with input/output data through the S3 protocol using Pachyderm’s S3-protocol-enabled pipelines.
About #
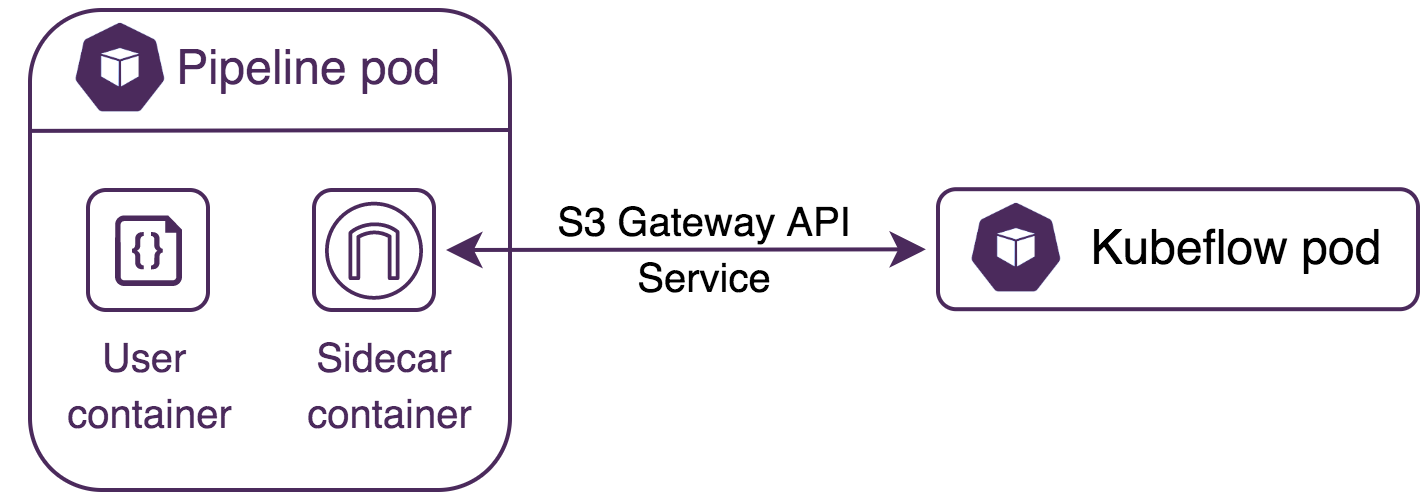
Pachyderm’s S3-protocol-enabled pipelines run a separate S3 gateway instance in a sidecar container within the pipeline-worker pod. Using this approach enables maintaining data provenance since the external code (e.g., within a Kubeflow pod) is executed in (and associated with) a Pachyderm job.
When enabled, input and output repositories are exposed as S3 Buckets via the S3 gateway sidecar instance.
- Input Address:
s3://<input_repo_name>. - Output Address:
s3://out
Example with Kubeflow Pod #
The following diagram shows communication between the S3 gateway deployed in a sidecar and the Kubeflow pod.
Configure an S3-enabled Pipeline #
- Open your pipeline spec.
- Add
"s3": truetoinput.pfs. - Add
"s3_out": truetopipeline. - Save your spec.
- Update your pipeline.
Example Pipeline Spec #
The following spec example reads files in the input bucket labresults and copies them in the pipeline’s output bucket:
{
"pipeline": {
"name": "s3_protocol_enabled_pipeline"
},
"input": {
"pfs": {
"glob": "/",
"repo": "labresults",
"name": "labresults",
"s3": true
}
},
"transform": {
"cmd": [ "sh" ],
"stdin": [ "set -x && mkdir -p /tmp/result && aws --endpoint-url $S3_ENDPOINT s3 ls && aws --endpoint-url $S3_ENDPOINT s3 cp s3://labresults/ /tmp/result/ --recursive && aws --endpoint-url $S3_ENDPOINT s3 cp /tmp/result/ s3://out --recursive" ],
"image": "pachyderm/ubuntu-with-s3-clients:v0.0.1"
},
"s3_out": true
}
User Code Requirements #
Your user code is responsible for:
- Providing its own S3 client package as part of the image (boto3)
- reading and writing in the S3 Buckets exposed to the pipeline
Accessing the Sidecar #
Use the S3_ENDPOINT environment variable to access the sidecar. No authentication is needed; you can only read the input bucket and write in the output bucket.
aws --endpoint-url $S3_ENDPOINT s3 cp /tmp/result/ s3://out --recursiveTriggering External Pipelines #
If Authentication is enabled, you can access the AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY env vars in your pipeline user code to forward your pipeline’s auth credentials to third-party tools like Spark.
Constraints #
- All files are processed as a single datum, meaning:
- The
globfield in the pipeline must be set to"glob": "/". - Already processed datums are not skipped.
- The
- Only cross inputs are supported; join, group, and union are not supported.
- You can create a cross of an S3-enabled input with a non-S3 input; For a non-S3 input in such a cross, you can still specify a glob pattern.
- Input bucket(s) are read-only, and the output bucket is initially empty and writable.